
Повторяющиеся слова в верстке
Одной из причин, в результате которой «ломается» верстка, является наличие повторяющихся слов в рукописи. Подумаешь там, автор два раза подряд написал слово «как», и всего-то в одном месте — вроде небольшая беда, но удаление этого повтора может привести к уменьшению числа строк в абзаце, и сразу же далее по всему материалу вылезают строки-вдовы и строки-сироты — т.е. вся твоя работа по вгонке-выгонке летит коту под хвост.
Так вот, повторяющиеся слова! После импорта текста в Индизайн хорошо бы проверить их наличие. И сразу удалить. И уже потом приступать к верстке.
Выполнить такую процедуру, как вы уже догадались, можно при помощи GREP.
Найти: \b(\w+)\s+\1\b
Заменить: $1
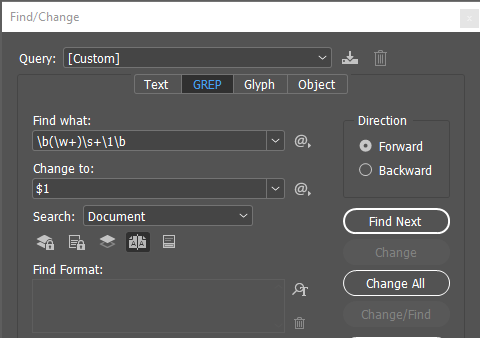
Краткая расшифровка:
\b — в пределах слова;
( — начало группы;
\w — любая буква слова (цифры и др. символы исключены);
+ — повторение. Один или более раз;
) — конец группы;
\s — любой пробельный символ;
\1 — указывает на найденное в первой группе — (\w+).
Возможно, что после такой проверки число «засад» для верстальщика станет меньше.
Наше полезное GREP-выражение было найдено в интернете на этой странице.


 Скрипты Михаила Иванюшина
Скрипты Михаила Иванюшина Object Model") InDesign ExtendScript API Adobe InDesign 2020 Object Model
InDesign ExtendScript API Adobe InDesign 2020 Object Model Indesign Snippets
Indesign Snippets{kind=link}
(CS5) К сожалению находятся и повторяющиеся группы цифр разделенные пробельными символами (цифры и др. символы НЕ исключены). То есть могут пострадать как телефонные номера, так и табулированные данные. Значит возможно только интерактивное использование.
\b([\l\u]+) +\1\b — так попробуйте (вместо \w ставим [\l\u])
Да. Так мы конечно спасём цифры, но не текстовые данные на табуляторах (типа простеньких «текстовых» табличек). Штука безусловно полезная, но не для полностью автоматического использования.
По моему опыту повторяющихся слов не так уж много и бывает, поэтому нет необходимости сразу автоматом делать все замены. Хотя чисто теоретически любой пробел \s в том выражении можно заменить на обычный пробел или собрать все виды пробелов в квадратные скобки, исключая ненужные.